在座的AI服务器那么多,为什么戴尔易安信PowerEdge XE8545这么能打?
1968年世界诞生第一个智能机器人。
2016年机器人击败世界围棋冠军。
如今,当你对着导航说出目的地、当你的邮箱里垃圾邮件明显减少;当你用人脸识别快捷支付、当你打开社交媒体就能看到自己感兴趣的内容……
凡此种种,我们无法否认是AI带给我们的便利,其背后都是AI服务器作为基础设施提供强大的支撑。
企业在向AI解决方案过渡中面临严重挑战
国际数据公司(IDC)发布2020H1《全球人工智能市场半年度追踪报告》(《Worldwide Semiannual Artificial Intelligence Tracker》),报告显示,2020上半年全球人工智能服务器市场规模达到55.9亿美元,占人工智能基础设施市场的84.2%以上,成为AI基础设施的需求主体。IDC预计,未来人工智能服务器市场将持续保持高速增长,在2024年全球市场规模将达到251亿美元。
通过IDC调研发现,超过九成的企业正在使用或计划在三年内使用人工智能,其中74.5%的企业期望在未来可以采用具备公用设施意义的人工智能专用基础设施平台。
Gartner的调研也印证了这种紧迫趋势,Gartner《全球IT行业2020年预测》:虽然只有35%的受访者表示他们已经部署了人工智能(比如NLP,ML,图形化技术等),但仍有52%的受访者表示,他们将在接下来的12个月内进行部署。
但正如硬币也有另一面:
IDC在《新兴技术和趋势的影响:人工智能》白皮书中也提到:“截至2025年,90%的应用程序预计将在5年内使用人工智能技术,然而,与此同时,却只有不到15%的组织正在活跃地使用人工智能技术。”
从某种程度上来说,在云厂商定制AI服务器之外的企业级市场,潜力巨大但潜在的用户需求无法充分得到满足,企业在向AI解决方案过渡中面临严重挑战。
如果有一句话来总结那就是:人工智能项目进展缓慢,尽管其各项IT功能十分完备。
为什么呢?
人工智能训练需要与时俱进的架构和设想
1872年世界上诞生了一位伟大的数学家,他总能跳出常规思维发现数学的奥秘,他导出的公式后来总是被人证明正确无误,他就是拉马努金。如果你对他的名字还陌生,但你只要知道“黄金分割点“是他的伟大发现之一就足矣。
面对人工智能市场庞大的需求和项目进展缓慢的某种错位,我们不仅要问,真正的“黄金分割点“在哪里?而谁又是发现它的主角?
戴尔易安信认为成功的人工智能项目遵循五大层次结构的模式:
IT环境:包括部署在私有云、公有云还是边缘侧?延迟和吞吐量大约是多少?
软件生态系统:如何将训练的模型投入生产?
模式:哪种模式和方式比较有效,数据科学家可以使用哪些工具可以建立、训练和证明这些模型
数据:有哪些数据可以用?存储在什么地方?需要做哪些准备?
用户案例:对未来的影响是什么?它是可行的吗?将如何衡量成功?
这意味着现代基础设施设计必须与特定的软件需求相匹配,人工智能训练需要与时俱进的架构和设计来克服深度学习、机器学习、分析以及推理中的关键难点。
调优是解决难点的最优解
事实上,AI工作负载的数据处理是一个循环的过程,它包含着数百万个不那么复杂的计算,同时也需要组织并行操作和快速移动数据,而数据通过硬件系统及其组件的速度越快,就可以处理得越快。
此外,服务器中的CPU、GPU、内存、存储也必须保持和其它组件相近的速度来执行任务,这样才能消除瓶颈,提升处理的速度。
这就是为什么对于AI工作负载来说,最重要的一个因素是并行I/O吞吐量(Throughput)。因为AI工作负载的速度受制于系统中最慢的组件,所以优化配置服务器中的组件就显得非常重要。
通俗的来说,就是在保持原有物理设施基本不变的情况下,通过技术手段来提升效能。类比的话就是人尽其才、物畅其流,高效协同,谁也别拖后腿。
正如E企研究院最近开箱实测的戴尔易安信PowerEdge XE8545,是戴尔今年推出的15G服务器家族中,对GPU优化最充分的一款,通过结合计算、加速器、存储的优质组件,提高了系统的工作效率,实现了在数据流和计算可能性方面的突破。

这台PowerEdge XE8545的配置为:
- 双路AMD EPYC 7713 64核CPU,共128核、256线程,512MB三级缓存;
- 16条64GB DDR4-3200内存,共1TB,或者说,1024GB;
- 4个80GB的A100 GPU,共计320GB HBM2e内存;
- 8个1.6TB PCIe 4.0 SSD;
- 双端口100GbE网卡……


从配置中可以看出,PowerEdge XE8545的核心是两个代号Milan的AMD第三代EPYC CPU,和四个安培架构的A100 GPU,其特点都是采用台积电7nm工艺制造。
7nm工艺意味着在单位芯片面积内可以容纳更多的晶体管,但是太多了整个芯片的良率就成问题,AMD EPYC系列采用了多die组合的模块化设计,继承了上一代8个CCD和1个IOD的Chiplet(小芯片)设计,不到400亿的晶体管,分成9个小芯片,降低了每个小芯片的制造难度,灵活搭配。
而第三代EPYC处理器主要的变化发生在CCD内部。CPU核芯更为强大,通过Load/Store、前端、微操作Cache、分支预测、执行引擎、Cache预取等多个环节的累积改进,每时钟周期指令(Instruction Per Clock,IPC)的性能提升达到19%。
AMD EPYC CPU的另一个优点是率先支持PCIe 4.0,带宽比PCIe 3.0高一倍。对访问GPU等加速器、存储和网络非常重要。
就拿网卡来说,两个100GbE端口,如果是PCIe 3.0的话就需要2个x16的插槽,而PCIe 4.0一个搞定。对存储来说, NVMe SSD的单盘性能,可以提高一倍。
但是如果实现与GPU之间的互连,都要通过PCIe 4.0去CPU绕一圈,显然不太可取, PowerEdge XE8545配备的是SXM4版本的A100,彼此之间通过NVLink通信,带宽高达600GB/s,比PCIe 4.0又高一个数量级,关键是四个GPU之间彼此直连,时延就要短很多。
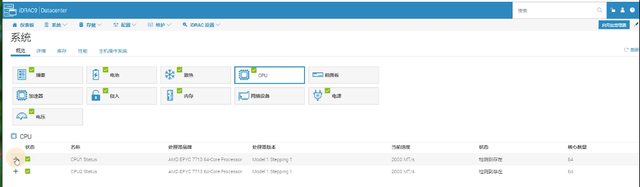
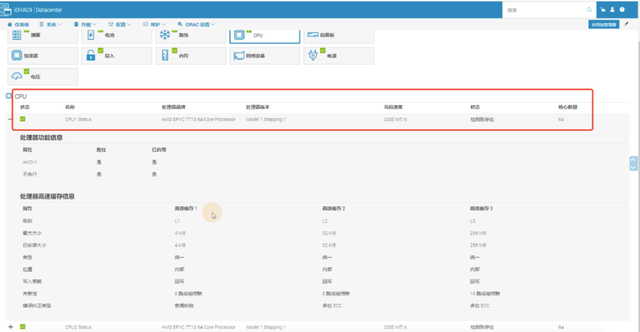

从图中可以看出PowerEdge XE8545的CPU、GPU、内存和存储的配置,作为追求高吞吐量的算力平台,PowerEdge XE8545目标工作负载主要是高性能计算(HPC)、人工智能(AI)中的机器学习和深度学习(ML/DL)、GPU虚拟化。
构建AI应用的强计算平台
很多AI开发、特别是训练深度学习神经网络,需要大量的计算。由于时间所限,我们从GitHub上下载了模型进行训练,运行了几个相对简单的训练任务,效果相当令人满意。
在A100其他推理性能增益的基础之上,仅结构化稀疏支持一项就能带来高达两倍的性能提升。
因为PowerEdge XE8545引入A100突破性的功能来优化推理工作负载,比如A100能在从FP32到INT4的整个精度范围内进行加速,多实例GPU (MIG)技术允许多个网络同时基于单个A100运行,从而优化计算资源的利用率。
在受到批量大小限制的极复杂模型(例如用于先进自动语音识别用途的RNN-T)上,显存容量有所增加的A100 80GB能使每个MIG的大小增加一倍(达到10GB),并提供比A100 40GB高1.2倍的吞吐量。
A100结合MIG技术可以更大限度地提高GPU加速的基础设施的利用率。借助MIG,A100 GPU可划分为多达7个独立实例,让多个用户都能使用GPU加速功能。使用A100 40GB GPU,每个MIG实例最多可以分配5GB,而随着A100 80GB增加的GPU内存容量,每个实例将增加一倍达到10GB。
由此验证PowerEdge XE8545的特质:
- 在加速的 I/O 吞吐量上,PowerEdge XE8545通过将其所有组件(NVLink、PCIe Gen 4.0 和 NVMe SSD)相结合,突破数据流和计算能力的界限。
- 采用低延迟的GPU点对点NVLink直连设计,搭载具有高速对等带宽 (600Gb/s) 的A100 SXM4 GPU,相较于当前的加速器,其机器学习性能6~7倍(HPC性能提高 2 倍)。
- 基于稀疏矩阵乘法和 600 GB/s 的 GPU 到 GPU 通信带宽(比上一代产品提高 2 倍),机器学习训练的性能提高了性能提高了 20 倍。
巧妙设计带来“节能”高价值
低碳与可持续发展是目前用户选择高价值产品的重要参考指标,在追求算力的同时,能耗问题一直是用户的关注点。
强劲的CPU+GPU组合,其实给服务器的设计带来了很大的挑战。
PowerEdge XE8545支持顶配280W TDP(热设计功耗)的AMD EPYC处理器,再加上内存后满载功耗超过600瓦。在E企业研究院实测的这台机器中,64核的AMD EPYC 7713,TDP为225瓦,两个也有450瓦。从戴尔易安信官方提供的数据来看,A100 80GB SXM版本的TDP,高达500瓦。
这样算来,总功率超过2千瓦,由此带来的供电和散热问题如何解决?
一是标准化的尺寸规格。为了容纳的计算和存储等组件,一部分厂商采用采用增加长度或宽度的做法,不过这对机柜和数据中心基础设施提出了额外的要求。
PowerEdge XE8545没有采用这些“取巧”的手段,仍然适用标准深度的机柜,避免用户产生前期改造和后期运维高昂的费用。代价是内部设计过于紧凑,又给散热设计带来了更大的挑战。

比如内部M.2 BOSS、OCP NIC 3.0,LOM和I/O卡,还有服务器的后下方,有4个2400瓦的白金级电源(PSU),它们可以两两一组,形成主备关系,保证供电的高可用。
二是巧妙设计,坚持使用最简洁的风冷。4U的PowerEdge XE8545,可以粗略的分为上下各2U。对于上面的双路CPU及其主板、内存而言,风冷效果可以,但下面2U对GPU来说有些捉襟见肘,戴尔为GPU配备了2.5U的散热器。

PowerEdge XE8545通过巧妙的设计,把4个A100 GPU及其基板放在主板的前面,这样前有前面板上10个2.5英寸驱动器下面的12个GPU风扇,后有6个系统风扇,前吹后吸,迅速带走GPU产生的热量。
PowerEdge XE8545的技术资料显示,使用500瓦的A100 80GB GPU,在25℃的环境下可以正常工作,最高不超过28℃;如果改用400瓦的A100 40GB GPU,环境温度可以提高到35℃,满足ASHRAE A2的标准。

在实测散热效果时,E企业研究院找了一个大会议室,打开窗户,没有强制通风,北京的秋天非常给力,连续好几天,服务器工作都很稳定,可能因为(在服务器内部的)位置更靠前的缘故吧,GPU进行训练任务的时候,温度比CPU还低。
第三是在简化管理上,PowerEdge XE8545具备完整的iDRAC和Open Management Enterprise(OME)支持,通过提供OpenManage全栈管理功能,简化了数据中心的运营。
通过iDRAC升级Dell EMC Power XE8545的BIOS
强安全保障强计算平台
对于企业级用户而言,数据安全和数据加密是重中之重。
在安全性上,PowerEdge XE8545具备高网络弹性的架构,通过 AMD 第三代EPYC处理器的安全功能,以防范Spectre(幽灵)、Meltdown(熔断)等漏洞造成的数据泄露风险,第三代EPYC处理器的安全内存加密 (SME) 和安全加密虚拟化 (SEV) 的平台支持增强安全性,可以保证用户对于数据的安全性,确保系统的安全可用。
第三代EPYC处理器Zen3架构持续运用了AMD在安全处理器核心上的设计,把处理器安全的集成到IO die上。同时,为密钥生成、密钥管理提供了加密功能,并通过启用硬件验证实现了以硬件信任更为基础的平台安全。
另外,用户可以通过偏差检测和系统锁定来检测和修复未经授权或恶意的更改,通过系统擦除,安全快速地从硬盘、SSD 和系统内存等存储介质中擦除各种数据。
通过E企业研究院实测, PowerEdge XE8545在性能、吞吐量、简化管理、安全集成以及散热设计上都有优秀表现,基于硬件和管理创新的能,PowerEdge XE8545搭载最新AMD第三代EPYC CPU和SMX4版本的A100 40/80GB GPU,对于尖端机器学习模型,复杂的高性能计算(HPC)和GPU虚拟化来说将是极佳选择。
现在,你应该已经明白,戴尔易安信PowerEdge XE8545为什么这么能打了吧。