十万预算部署DeepSeek一体机,靠不靠谱?
DeepSeek的火爆极大促进了大语言模型在千行百业的落地。
首先是有了使用的信心。DeepSeek-R1推理模型已经拥有6710亿参数规模,符合“参数越多越智能”的认知,而且有实际测试表现和广泛的使用反馈作为佐证,让大家相信这个开源模型已经足够好了。其次是完全开源,不论是直接使用,还是用作基础模型进一步微调、后训练,都没有法律风险。其三是丰俭由人,提供了671B全量模型,以及覆盖70B、32B、7B等不同规模的蒸馏模型,还有若干低秩量化版本,可以满足不同推理质量和算力资源的要求。
模型开源,独享更香
应用的热情盘活了大大小小云厂商的算力资源,随着公开的DeepSeek服务纷纷瘫痪,连付费客户都大受影响。公有云“掉链子”引发的群体焦虑进一步催生了私有化部署的热潮:云厂商积极打包算力和服务,主打低门槛和弹性;硬件厂商纷纷推出各式“推理一体机”,开箱即用。
自持资源的可及性、可靠性是私有化部署的重要原因,但更长远地看,根本原因还是数据隐私与法规的要求。姑且不说公有云服务商在用户协议中的霸王条款,即使是私有云也会面临数据上传外网的合规限制。
利用大模型审查商业合同、法律文书,对病历、科研数据进行总结,都能明显节省时间,但恰恰都面临隐私和法律风险。对于这类需求,在本地部署DeepSeek推理一体机是一个很好的选择,而且,门槛并不高。
基于英特尔至强W处理器、2~4块GPU卡构建的推理一体机,预算在十万元左右,便可以支持数十人并发使用的需求,满足中小型企业全员上AI的需求。
如何构建高性价比算力底座
英特尔至强W是单路处理器,采用全大核、大缓存的架构,可以提供多达60核、112.5MB L3缓存(W9-3595X),睿频加速可达4.8GHz,甚至部分后缀为X的型号还可以进一步超频。
对于推理一体机,至强W的高扩展性得到了充分发挥。它支持8通道内存,内存容量可以达到4TB;112条PCIe 5.0通道,可以配置4到7块高性能GPU卡,不但可以加载较大参数规模的模型,还可以提供可扩展的吞吐量。
以搭配英特尔Arc A770 16GB卡为例,单卡已经可以部署7~14B蒸馏模型;双卡可以部署32B蒸馏模型;4卡即可使32B蒸馏模型的推理输出达到500~800 Tokens/s的水平。在中文环境下,每个Token相当于0.75~1.8个汉字。以500Tokens/s、每Token对应1个汉字计,这就相当于每分钟输出3万汉字。这个输出能力足够满足20到50人的并发请求。
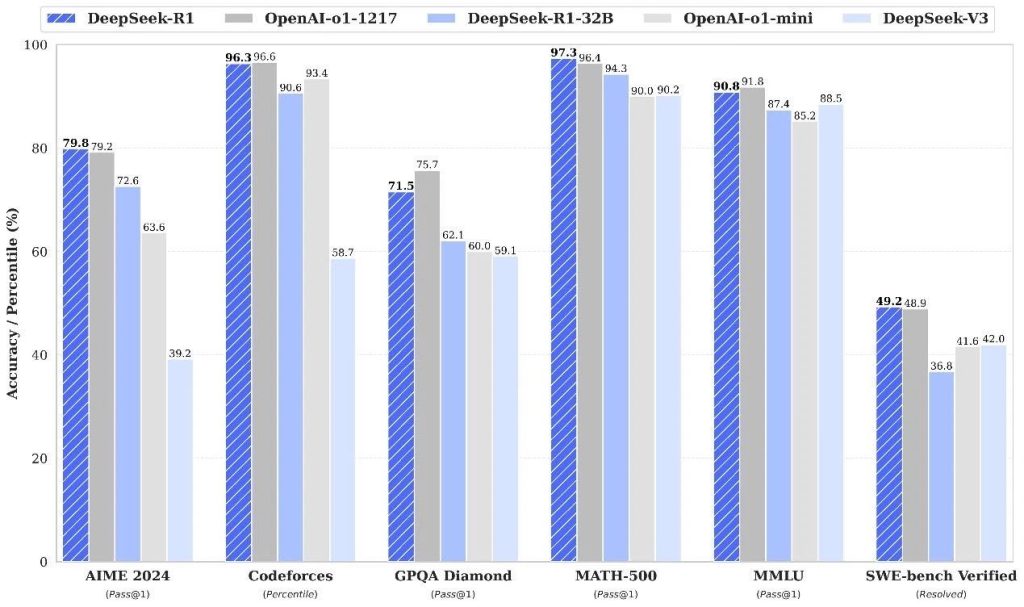
这里以部署DeepSeek-R1-32B为目标,是因为这个规模的蒸馏模型已经在多数测试项目中超过了OpenAI-o1-mini,在实践中也证明可以比较高质量地完成长文本处理、代码生成等任务。以审查合同、会议纪要为代表的严肃工作可以交由部署32B大模型的一体机完成,而不再需要担心隐私泄露甚至违法的风险。
如果搭配24GB显存的加速卡,还可以部署70B蒸馏模型,吞吐量以千计,部分显存位宽较大的卡可以达到2000Tokens/s以上,完全能够满足百人量级的同时使用需求。70B模型可以完成长文本生成、创意辅助等高质量的工作。另外,较大的显存容量除了可以部署一个较大规模的模型,也可以实现在一体机内部署多个不同规模、不同特点的中小型模型,以满足不同类型用户的需求。
值得一提的是,借助KTransformer为代表的开源大语言模型推理优化框架,基于至强W的推理一体机还可以运行“满血版”的DeepSeek-R1,以支持对推理精度要求最高的任务。这类优化框架可以让GPU和CPU共同分担计算任务,并将一部分模型参数放置在容量较大的主内存。以使用单条96GB DDR5 RDIMM为例,至强W的八个内存通道可以实现768GB的内存容量和307GB/s的内存带宽,独立部署FP8精度的DeepSeek-R1 671B完全没有问题,更不用说Q4、Q2量化版本了。
随着KTransformer这类优化框架的不断开发,还有机会进一步发挥至强W内置的AMX(Advanced Matrix Extension)加速器的优势,进一步提升推理吞吐量。至强W-2400/3400正式开始引入AMX,可以每个时钟周期内进行2048次并行运算,在神经网络推理、机器学习当中已经展现了不错的实用性。
产品案例
根据并发用户数、模型规模,可以配置不同的CPU内核数量和GPU显存容量,以满足各种类型用户、不同场景的需求。
- 至强W5+2×Arc A770方案:可部署14B蒸馏模型提供文档识别、智能问答等服务。如果部署32B蒸馏模型,可为20人以内的部门、小型企业提供较高质量的、不太频繁的文本服务,譬如合同审查等。随着应用需求提升,用户也可进一步升级为四卡配置。
- 至强W5+4×Arc A770方案:建议部署32B蒸馏模型,由于处理能力和显存充裕,推理批次可以大幅提升,速度达520~780 Token/s,可以满足上百人规模的中小型企业使用,可以用于涉及大量文档检索、归纳整理之类的知识管理型的工作,以及代码辅助等场景。
- 至强W7+4×Arc A770方案:增加CPU的内核数量,以支持数百人规模企业,并发处理30~50个用户请求,适用于医疗、律所等专业文书的分析、生成场景。
- 至强W9+96GB显存方案:96GB显存可以通过6块Arc A770,或4块其他24GB显存的加速卡构成。这样的配置支持70B参数模型部署,吞吐量可以达到1500~2400 Tokens/s,可以满足中、大型企业内多个部门高质量、高吞吐、高并发的需求,可以用于知识图谱、长文本生成等场景。

目前宝德、超云、长城、倍联德、昱格、智微智能等多家厂商已推出基于至强W处理器+四卡的DeepSeek一体机。一体机搭配多种蒸馏模型的应用落地,已经获得上下游厂商和用户的共同验证,日臻成熟。
基于Xeon W高效部署满血版DeepSeek-R1模型的工作也在不断进行,敬请期待。