国鑫4090服务器性能提升35% 推理效率/能效实现双飞跃
惊爆:训推性能最高提升35%!
春节过后,国鑫宣布:通过全栈垂直优化技术,国鑫全系列8卡GPU服务器的 NCCL(NVIDIA Collective Communications Library)性能最高提升35%,整机NCCL带宽最高达26GB,AI推理效率与能效比实现跨越式突破。
并且,基于DeepSeek、llama2/3大模型实测验证,国鑫服务器在千亿参数级模型推理场景中效率最高能获得35%的提升,TCO(总体拥有成本)降低近30%。这一成果不仅刷新了国产服务器在AI算力领域的性能标杆,也意味着国鑫为大模型厂商的大模型推理的‘最后一公里’提供了关键助力。
垂直优化突破极限,NCCL性能直击大模型痛点
在AI大模型训练与推理中,多卡GPU间的通信效率是制约算力释放的核心瓶颈。国鑫研发团队针对NCCL底层通信协议、硬件拓扑结构与数据流调度机制展开全栈重构,通过动态负载均衡算法与低延迟通信路径优化。这一突破直接解决了大规模分布式训练中常见的“通信墙”问题,使千亿参数模型训推性能最高提升35%,为DeepSeek等超大规模模型的快速迭代提供了硬件级加速引擎。
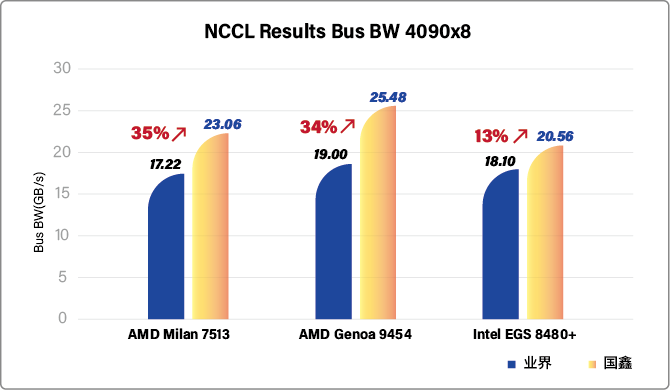
DeepSeek大模型实测:推理效率/能效双飞跃
为验证技术突破的实际价值,国鑫研发团队在DeepSeek 大模型上进行了全场景压力测试。结果显示:推理吞吐量最高提升35%:在相同硬件配置下,国鑫服务器支持每秒处理的Tokens数量显著增加,实时推理响应速度逼近毫秒级;
能效比优化35%:通过智能功耗调控算法与通信负载优化,单次推理任务能耗降低超1/3,助力企业实现绿色算力转型;长上下文任务优势凸显:在DeepSeek 擅长的长文本生成、复杂逻辑推理场景中,通信延迟降低使模型输出连贯性提升15%,用户体验显著优化。
TCO降幅可达30%:性能提升直接转化为企业降本增效——以单台服务器支撑的日均推理请求量计算,TCO降幅可达30%,这对规模化AI应用落地具有战略意义。”
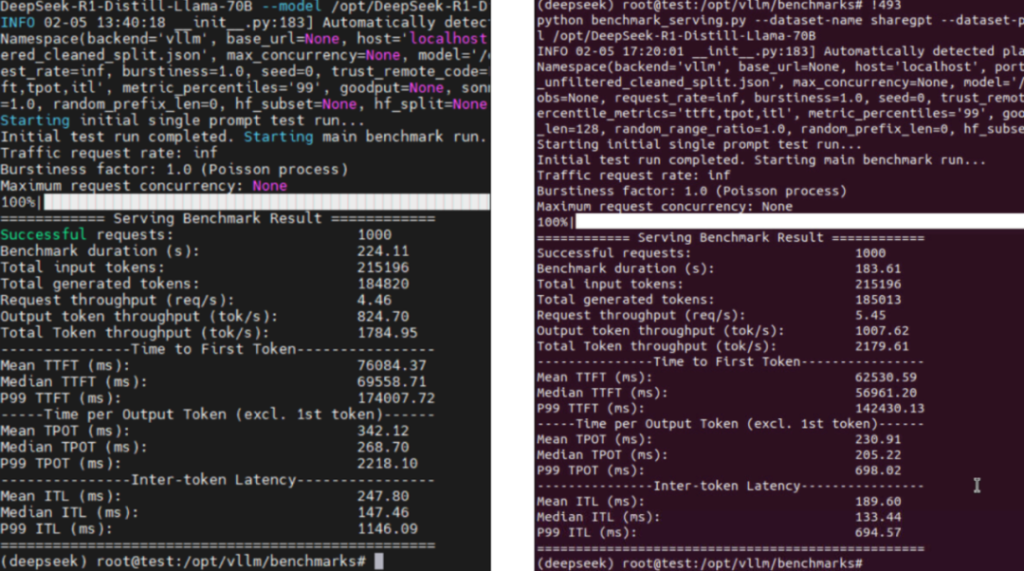
<优化前> <优化后>
行业共振:开启AI普惠化新纪元
随着AI大模型向万亿参数迈进,算力成本与效率已成为制约行业发展的核心矛盾。国鑫此次技术突破,直击“算力平民化”痛点——以30%的TCO降幅,企业可用同等预算部署多30%的算力节点,或将大模型推理成本拉入“分/千Token”时代,客户模型部署成本可降低数百万/年,AI应用 ROI(投资回报率)提升2倍以上。未来,国鑫将持续推动算力普惠化进程,探索更大规模集群的效能极限,为AGI(通用人工智能)时代夯实算力地基。(来源:国鑫)
