东数西算三计事,四代至强可扩展
从远程工作和学习成为必选项,到企业加速数字化转型,二十多年前提出的“数字化生存”在过去两年多中席卷全球。亿万大众和千行百业源源不断产生海量的数据,对算力的需求也持续增长,需要更高效的利用相对有限的资源。
国际数据公司(IDC)日前公布了2022~2026年的全球存储圈(StorageSphere)展望,据估算:2021年新增的存储容量达到7.9EB,其中约67%由企业管理;到2026年,这两个数字将分别上升至20.7EB和80%——由于越来越多的数据从消费者转向企业管理,整体的存储利用率也将从39%提高到42%。

2021-2026年全球存储装机容量增长趋势
(来源:IDC,2022)
随着保存在数据中心的数据占比越来越高,数据中心的统筹管理就成为进一步提高效率的关键。
工信部印发的《新型数据中心发展三年行动计划(2021-2023年)》要求,到2021年底,全国数据中心平均利用率力争提升到55%以上,总算力超过120 EFLOPS;到2023年底,两个指标分别为60%以上和超过200 EFLOPS,其中高性能算力占比达到10%。
2022年1月中旬和2月下旬,国家发改委、中央网信办、工信部、国家能源局分两批发出复函,先后同意内蒙古自治区、宁夏回族自治区、甘肃省、贵州省和京津冀地区、长三角地区、粤港澳大湾区、成渝地区启动建设全国一体化算力网络国家枢纽节点,并规划了10个国家数据中心集群,“东数西算”工程正式全面启动。
不难看出,跨区域的枢纽节点京津冀、长三角、粤港澳大湾区、成渝对应我国的四大经济区,从地理位置和人口分布上,属于“东数”;四个省级行政区域的枢纽节点贵州、内蒙古、甘肃、宁夏,地广人稀,资源丰富,属于“西算”。
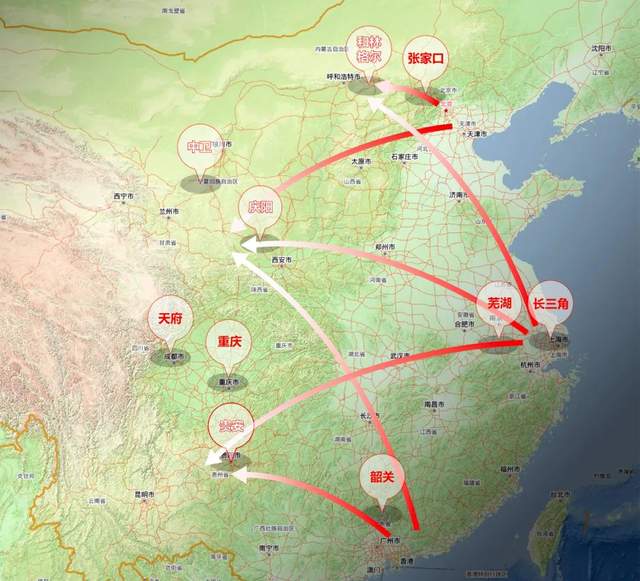
10个国家数据中心集群概略位置,以及“东数”、“西算”枢纽节点间的组对关系(来源:《2021中国云数据中心考察报告》,益企研究院)
在起步阶段,4个单一行政区域的的国家枢纽节点(“西算”区),原则上(各)布局1个集群;4个跨区域的国家枢纽节点(“东数”区),原则上(各)布局不超过2个集群。目前,我国最大经济区长三角和本身就是双头格局的成渝都已经规划了2个集群,所以一共是8个国家算力枢纽节点,设立10个国家数据中心集群。
“东数西算”工程的目标是布局建设全国一体化算力网络,国家枢纽节点之间进一步打通网络传输通道,优化东西部间互联网络和枢纽节点间直连网络,提升跨区域算力调度水平。国家枢纽节点以外的地区,统筹省内数据中心规划布局,与国家枢纽节点加强衔接,参与国家和省之间算力级联调度,开展算力与算法、数据、应用资源的一体化协同创新。
在城市城区范围,为规模适中、具有极低时延要求的边缘数据中心留出发展空间,确保城市资源高效利用。原则上,将大型和超大型数据中心布局到可再生能源等资源相对丰富的区域,优化网络、能源等资源保障。贵州、内蒙古、甘肃、宁夏等节点,重点提升算力服务品质和利用效率,充分发挥气候和资源优势,夯实网络等基础保障,积极承接全国范围需后台加工、离线分析、存储备份等非实时算力需求,打造面向全国的非实时性算力保障基地。
不难看出,“东数西算”工程的核心是分级(层)和互连,分级是手段,互连是保障。
分级:由近及远,逐层扩展
如果没有资源、成本等条件限制,数据中心当然在城市区、离人群近最好,就像数据如果就在CPU里肯定访问最快。但是,CPU啊CPU,真正的C位只有一个,中央区或者说核心区的容量也是非常有限的,大量运算所需的数据只能放在相对低速的内存(DRAM)里,而海量的“非实时性”数据则要存储在比内存还要慢几个数量级但容量也大几个数量级的SSD(固态盘)和硬盘里。这个道理,计算机体系架构和数据中心全国布局是相通的。
即使在CPU内部,存储资源也是分层的,从L1、L2到L3 Cache,容量逐级增大。得益于半导体技术的进步,Cache容量也会水涨船高。以5月英特尔On产业创新峰会开幕当日开始出货的代号为Sapphire Rapids的第四代英特尔® 至强® 可扩展处理器为例,与第三代至强® 可扩展处理器相比,不仅每个核心的L2 Cache容量增加了60%,由于核数有明显的增长,所有核心共享的L3 Cache(Last Level Cache,LLC)容量也增大60%以上,可以更好的处理数据密集型工作负载。

多年来,英特尔还采用引入新型存储介质的方法,努力缩小不同存储层级之间的容量和性能差异。第二代至强® 可扩展处理器引入了傲腾™ 持久内存(Optane Persistent Memory),第四代至强® 可扩展处理器将支持新一代的300系列傲腾™ 持久内存(PMem 300)。
傲腾™ 持久内存填补了传统内存(DRAM)与高性能存储(如SSD)之间的空白,第四代至强® 可扩展处理器通过在封装内加入高带宽内存(High Bandwidth Memory,HBM),又可以填补L3 Cache与DRAM之间的空白。HBM的带宽明显高于DRAM,时延也更短,且拥有数十GB的容量,在某些特定用例下甚至不需要使用DDR接口的DRAM。
在增加新的数据(存储)层级上,“东数西算”布局里“东数”区的数据中心集群有类似的效果。以京津冀枢纽的张家口数据中心集群为例,从北京市区(数据中心)访问的时延大约在2~3个毫秒(ms)多,按照《全国一体化大数据中心协同创新体系算力枢纽实施方案》(以下简称《实施方案》)的建议,可以承载实时交互型的业务需求。
互连:时延递进,带宽升级
衡量互连有两个核心指标:时延,带宽。
在数据中心的层面,时延最终受限于节点间的物理距离,时延越短的数据中心,可以部署的应用类型,受限制就越少。《实施方案》中有如下建议:
城区内:数据中心端到端单向网络时延原则上在10毫秒(ms)范围内。作为算力“边缘”端,优先满足金融市场高频交易、虚拟现实/增强现实(VR/AR)、超高清视频、车联网、联网无人机、智慧电力、智能工厂、智能安防等实时性要求高的业务需求;
区域内(东数):数据中心端到端单向网络时延原则上在20毫秒范围内。支撑工业互联网、金融证券、灾害预警、远程医疗、视频通话、人工智能推理等抵近一线、高频实时交互型的业务需求;
区域间(西算):贵州、内蒙古、甘肃、宁夏节点内的数据中心集群。优先承接后台加工、离线分析、存储备份等非实时算力需求。

结合上一节对张家口数据中心集群的介绍,不难看出,上述“数据中心端到端单向网络时延”的原则比较宽松,但总的原则基本成立。以城区来说,确实被业界视为边缘计算必争之地。
虚拟无线接入网(vRAN)是电信运营商将基带功能作为软件运行的一种方式,随着边缘计算和5G时代到来,vRAN面临着快速增长的需求。第四代至强® 可扩展处理器核心具有全新的5G特定信号处理指令增强功能,专为支持RAN特定信号处理而开发,可以使vRAN的容量增加两倍;该系列处理器还将采用集成加速功能的全新芯片,针对vRAN工作负载进行了优化。英特尔正与领先厂商合作,将基于第四代至强® 可扩展平台的全新解决方案推向市场。
与这些实时性要求高的业务需求相对,是可以跨区域部署的非实时性算力需求,譬如高性能计算(High Performance Computing,HPC)。E级超算(Exascale Computing,百亿亿次计算)是目前各先进国家努力的目标,美国阿贡国家实验室的极光(Aurora)超级计算机基于内置高带宽内存(HBM)的英特尔® 第四代至强® 可扩展处理器和代号为Ponte Vecchio的英特尔® 数据中心显卡,能够提供每秒超过两百亿亿次的双精度峰值计算性能,英特尔® oneAPI亦为开发者提供无缝的系统集成。
将这些大规模的超算系统部署在贵州、内蒙古、甘肃、宁夏等可再生能源丰富、气候适宜、数据中心绿色发展潜力较大的(西算区域)节点,不仅可以助力解决人类面临的疑难问题,如更准确地预测气候以及发现应对癌症的新疗法,还能有效的减少碳排放,保护我们生存的环境。
在带宽方面,第四代至强® 可扩展处理器也进行了全面的提升,具有更高的吞吐能力:
- 多CPU扩展:用于CPU之间互连的UPI 2.0,数量和带宽都比前代产品有明显增长,支持8路系统;
- 内存通道:升级为DDR5,带宽提升50%以上;
- 存储和网络I/O:PCIe 5.0,带宽翻倍,可以支持更高速的网卡(如800G)和存储设备;
- 还引入了CXL(Compute eXpress Link)1.1,支持加速器和内存扩展。
类比一下,如果京津冀到长三角,乃至扩大到8个国家级枢纽之间,互连的带宽提高一倍,将为数字经济的基础设施,带来何等显著的升级效果。
卸载:五大引擎,各有专精
分级更多的是从数据的角度来说,在解决了互连的问题之后,各大国家数据中心集群可以卸载一部分核心城市的算力需求,让核心城市的算力资源可以集中在最需要的应用上。
从CPU的角度也是如此,第四代至强® 可扩展处理器集成了5大加速器,可以卸载一些专用任务,让CPU的核心资源能尽可能的用于业务应用。
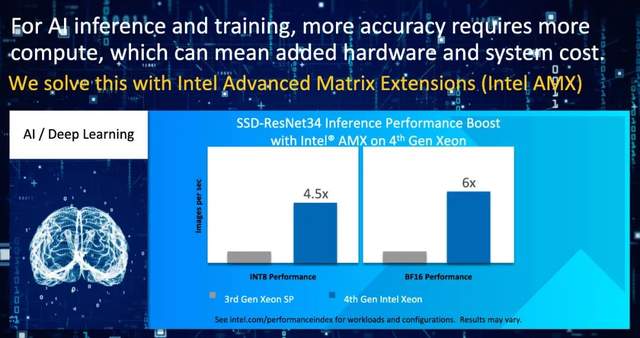
AI推理对时延的要求较高,是在边缘端高发的工作负载。第四代至强® 可扩展处理器集成AI加速引擎AMX(Advanced Matrix Extensions,先进矩阵扩展),对AI推理进行全方位的优化,与第三代至强® 可扩展处理器相比,INT8数据类型的性能达到4.5 倍,BFloat16 数据类型的性能提高了6倍。
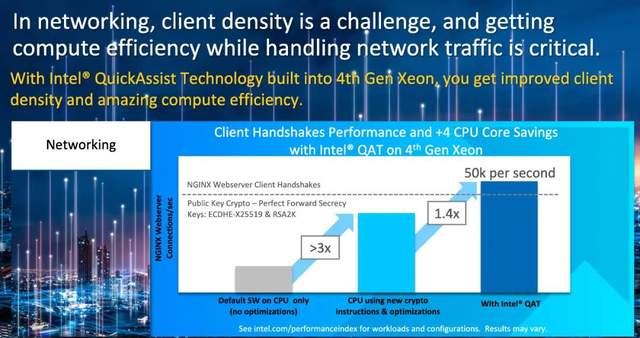
在数据中转的过程中,譬如vRAN、数据包处理、CDN等使用场景,需要越来越多的连接,以更高的吞吐量来解决客户端密度的挑战。第四代至强® 处理器加入了QuickAssist Technology Accelerator(QAT),借助新的加密指令和软件增强功能,会获得比使用标准内核、标准指令高3倍左右的性能。QuickAssist结合公钥加密功能,与只使用CPU内核相比,会额外获得40%的性能提升;同时,还可以释放节点中4个额外的核心,用于处理其他生产性工作。
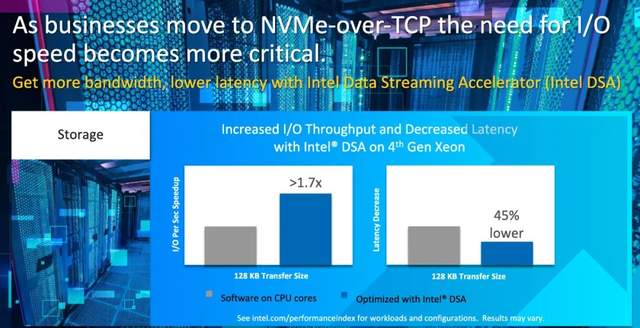
其实,在数据存储的环节,也有大量的工作基本是在移动数据。第四代至强® 处理器加入了数据流加速器(Data Stream Accelerator,DSA),让应用可以将这些数据活动从CPU核心卸载到加速器。数据表明,DSA引擎可提供比核心高1.7倍的性能,并能将整体时延降低 45%。用户也可以在系统中使用4个或更少的核心,获得相同级别的性能。
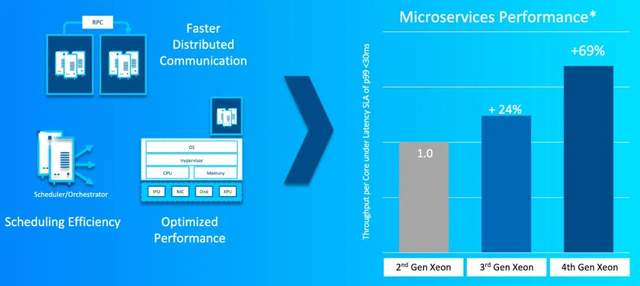
在这个云计算的时代,超过80%的新的云原生和SaaS应用预计将以微服务(microservice)的形式构建。第四代至强® 可扩展处理器为微服务的弹性计算模型而构建,上面提到的DSA可帮助用户更高效、更快速地在容器中启动和报废微服务,而QuickAssist技术可以整体降低通信需求的时延。新的AIA(Accelerator Interface Architecture)指令可以更有效的分配加速引擎的卸载工作,使得第四代至强® 处理器提供的微服务性能达到了第 99 个百分位的时延要求,性能比第二代至强® 处理器提升了69%,比第三代英特尔® 至强® 可扩展处理器也提升了35%以上。
同时,英特尔® 软件防护扩展(Software Guard Extensions,SGX)大大增强了数据防护能力和应用,能够确保数据在多租户等环境中的安全性。
使用第四代至强® 可扩展处理器内置的加速器,可以释放CPU核心用于处理其他生产性工作,也可以减少使用的核心数量来获得相同的性能。用户无需再为特定的使用场景添加扩展卡加速器,就可以获得更高性能、更大吞吐量,或者部署更少的服务器达到相同的效果,从而减少数据中心整体的占用空间、功耗和冷却需求,符合东数西算节能降碳的潮流。
诞生于“东数西算”时代的数据中心,你们做好迎接第四代至强® 可扩展处理器的准备了吗?